
Introduction
Private large language models are specialized versions of natural language processing tools maintained within an organization. These private models offer customisation for specific tasks, enhanced security and compliance for sensitive data, and can be optimised for the organization's unique hardware and resources. Although they may involve significant costs and maintenance, private models allow for deeper integration with existing systems, better alignment with ethical guidelines, and protection of intellectual property.
In interplay we provide nodes to build private LLM model based applications. These will help to integrate knowledge base from an organization in vector database format and models to function based on these knowledge base.

Features and Models
In a private large language model (LLM), various features are implemented to enhance its performance and usability. Reducing hallucinations helps in providing more accurate and reliable outputs by minimizing the generation of false information. The complexity of the model is reduced to make it more efficient and accessible, contributing to improved answering time for quicker responses. Distillation techniques are employed to create more compact representations of the models, optimising their performance without losing essential information. Handling a private knowledge base ensures that proprietary or sensitive data is processed securely within the system. The model's ability to handle multiple file formats adds versatility in interacting with various data types. Intelligent prompt selection enables more context-aware and relevant interactions, while history handling maintains a coherent and continuous conversation or processing flow. Together, these features contribute to a robust, efficient, and intelligent private LLM tailored to specific organisational needs.
Currently we have 2 types of models supported in the interplay:
- Fine tuned model for specific purpose (Eg : ChatBot).
- FlanT5-248M-With-Custom-Alpaca
- FlanT5-248M-With-Custom-Greeting
- General purpose models from Hugging face.
- MPT-7B
- FlanT5-XL
- Falcon-7B
- DollyV2-7B
- LLaMA2-7B
Model Configuration
General purpose models are loaded from the hugging face directly while fine tuned models need to be uploaded from local machines or cloud platforms in zip file format. The following steps have to be followed for uploading fine tuned models.
Step 1

Initially, create the above flow using the LLM-Initiate-Project and LLM-Model-Downloader nodes.
Step 2
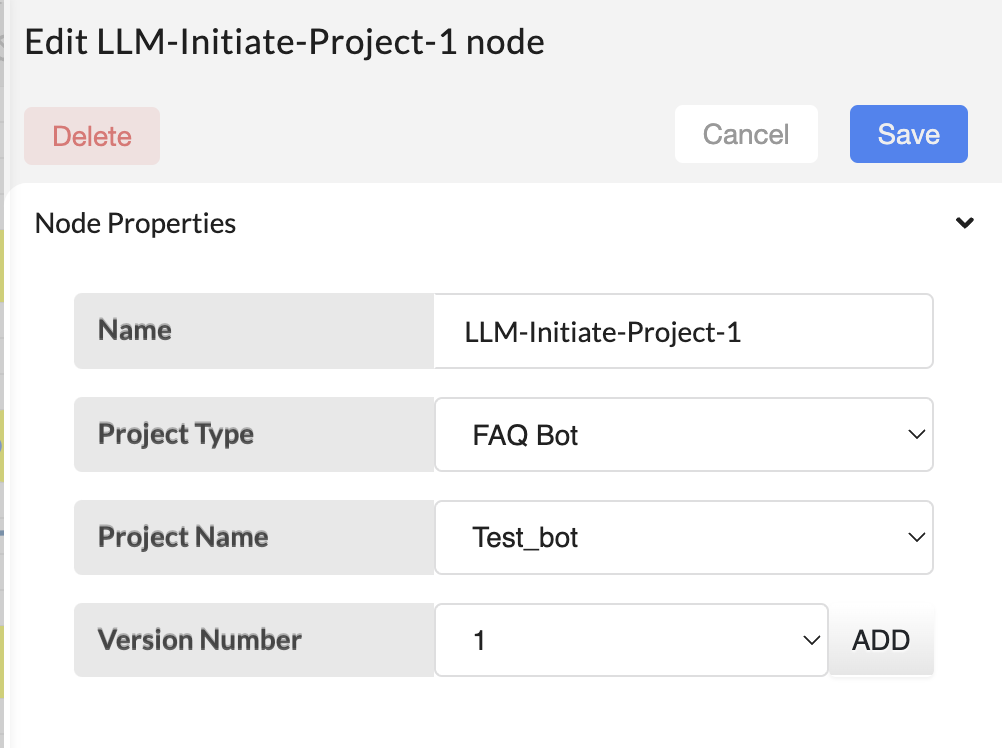
Next step is to provide a Project name and Project type in the LLM-Initiate-Project-1 node.

- Project Type - Choose project type as FAQ bot for chat bot
- Project Name - choose an existing project or add a new name for a new project.
- Version Number - Add versions for existing projects.
Step 3
Next step is to provide the model details, platform credentials and location details for downloading the model.
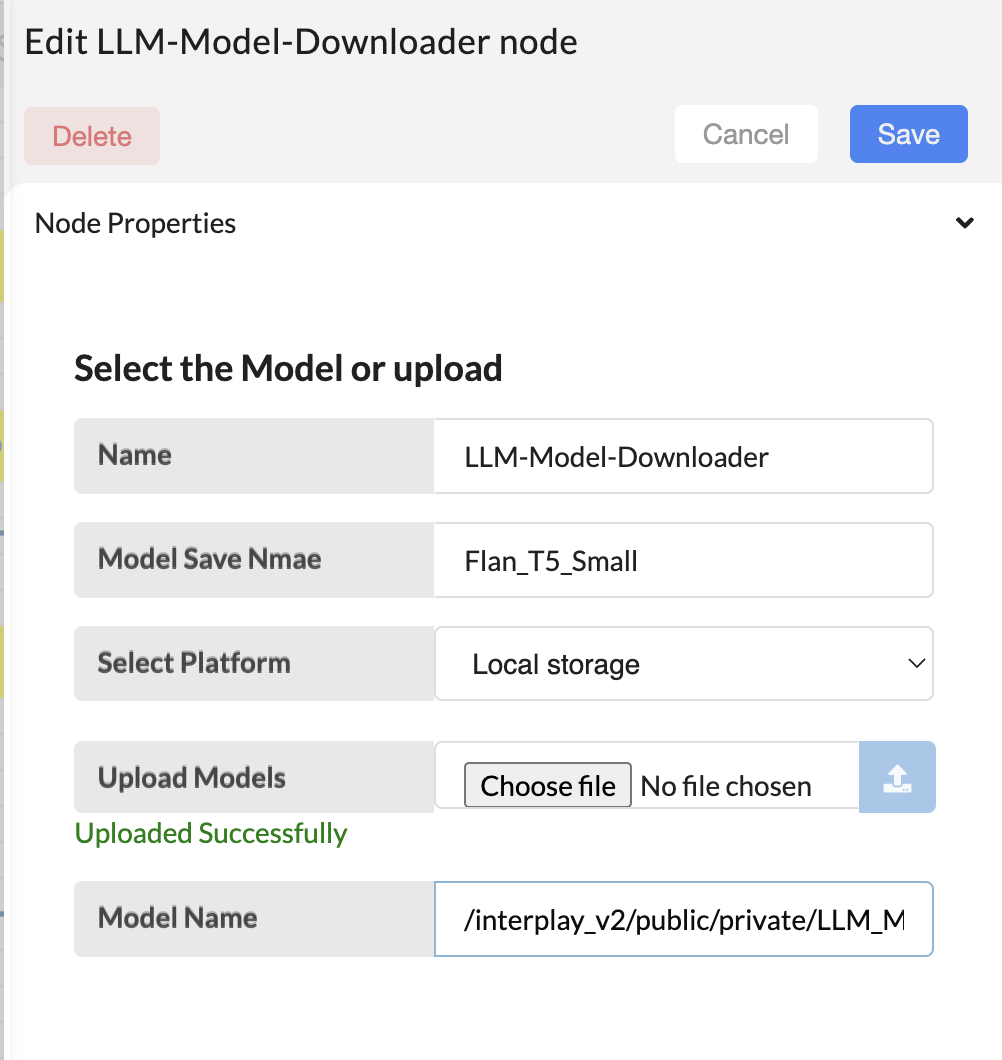
- Model save name - A name to save the uploaded LLM model
- Select platform - Select between platforms such as Interplay, S3 bucket , Google cloud storage, Local storage (Upload from local computer).
- Upload Models - choose the zip file containing the tuned model files.
- Model name - shows the uploaded file name and directory to verify.
- Other than Interplay and Local storage it needs to provide the credentials and file paths for downloading the model.
Knowledge onboarding
One of the common applications using Private LLM is to use a specific knowledge base like menus , organization information etc to answer questions. This information can be in different file formats, which can be handled by our application. Chroma db Vector database is used to store the data. It provides more accurate semantic search for knowledge retrieval in less time.
Embedding models convert the documented data into embedding vector.

Available Embedding models
- all-mpnet-base-v2
- multi-qa-MiniLM-L6-cos-v1
- All-distilroberta-v1
- Instructor-xl
- multi-qa-mpnet-base-v1
Building Database contains two parts
- Data downloading
- Database creation
Part -1 Data Downloading
Step -1
In this flow you can upload files needed for knowledge into a folder

Initially, create the above flow using the LLM-Initiate-Project and LLM-Model-Downloader nodes.
Step -2
Next step is to provide a Project name and Project type in the LLM-Initiate-Project-1 node .
Step -3
Configure the LLM-Data-Downloader to download the data in the project for database.

- Dataset Type - select database for build the database.
- Data-set name - create a new dataset or select existing data sets to add files.
- Select platform - Select between platforms such as S3 bucket , Google cloud storage and Local storage (Upload from local computer).
- Upload file - choose a file in the local directory. If select platform is local storage
- Other than Interplay and Local storage it needs to provide the credentials and file paths for downloading the model.
After finishing the part-1 steps trigger the flow. The data files will be uploaded in the project.
Part -2 Database creation
Step 1
Following flow need to be created to generate vector database from the knowledge base :
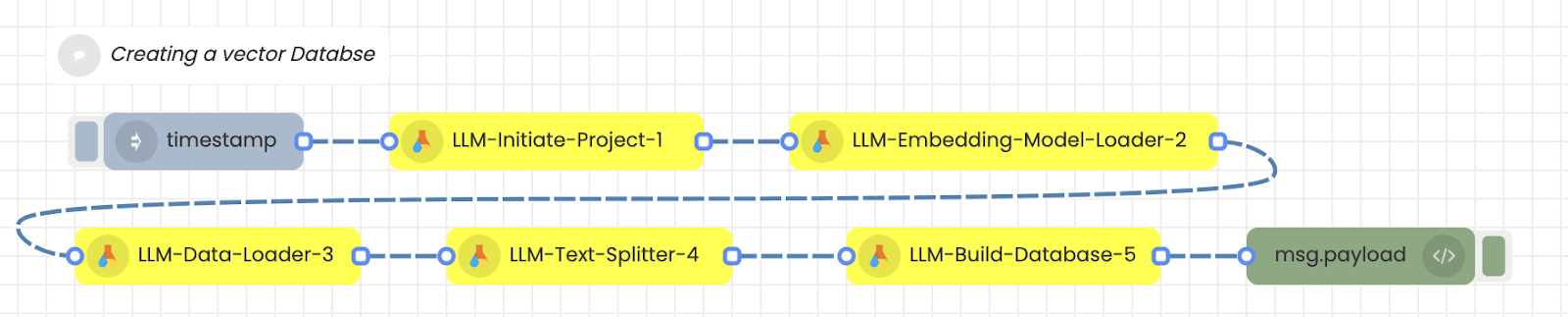
Step 2
Next step is to provide a Project name and Project type in the LLM-Initiate-Project-1 node .
Step 3
Configure the LLM-Embedding model loader. It will load the specific model for embedding.
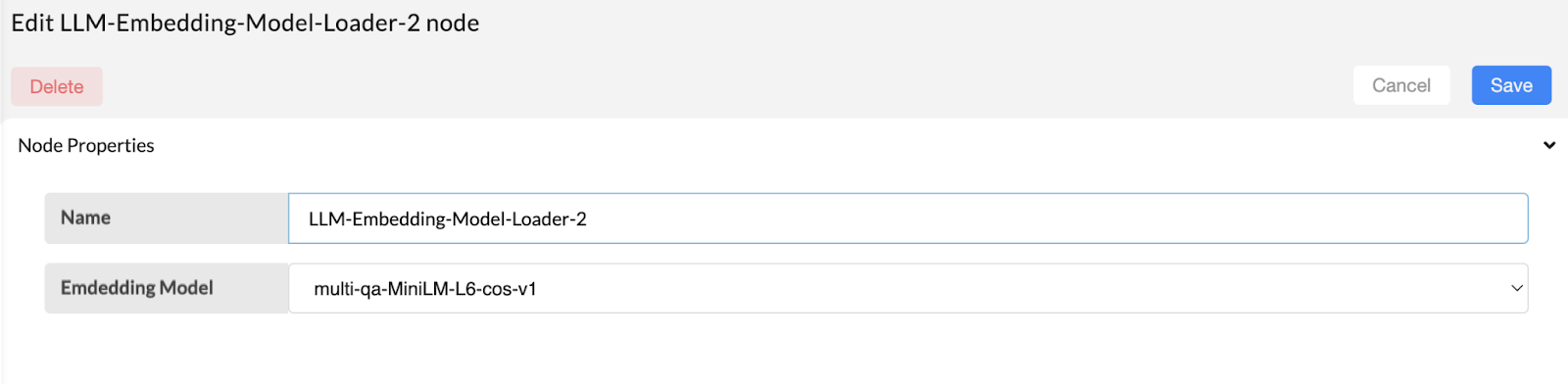
- Embedding model - choose the embedding models as your preference. Currently it has five models.
Step 4
Next step is to configure the LLM-Data-downloader node. Select a suitable created dataset for the database.
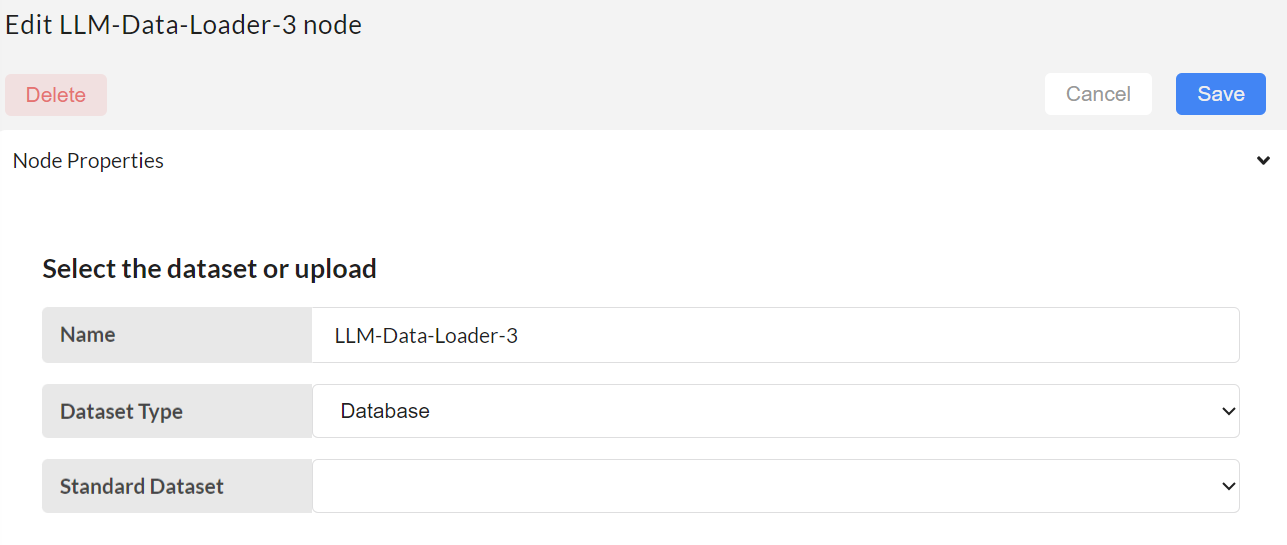
- Standard Dataset - select a dataset from already created datasets for the new database.
Step 5
Next step is to configure the LLM-Text-Splitter-4 node. It is used to split the content in multiple documents if it is too long.
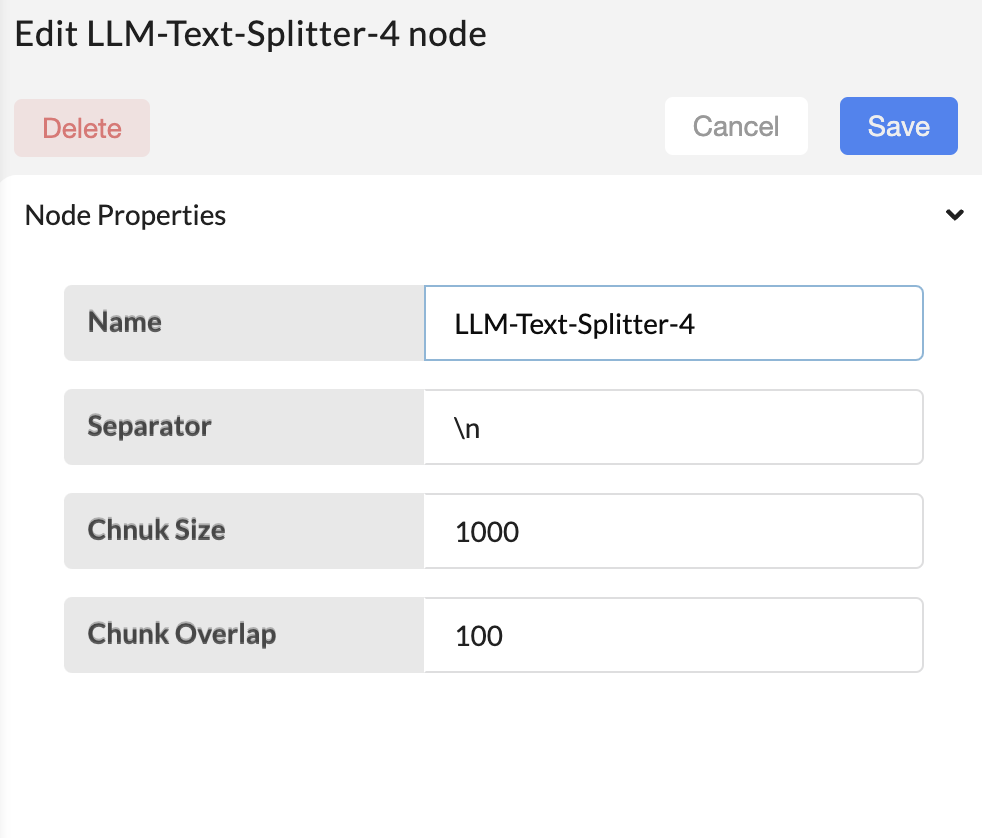
- Separator - specify the separator to split the content into chunks.
- Chunk size - maximum limit of the chunks.
- Chaunk overlap - overlap chunks while doing the splitting for the continuity. It specify the overlap chunk size.
Step 6
Next step is to configure the LLM-Build-Database node
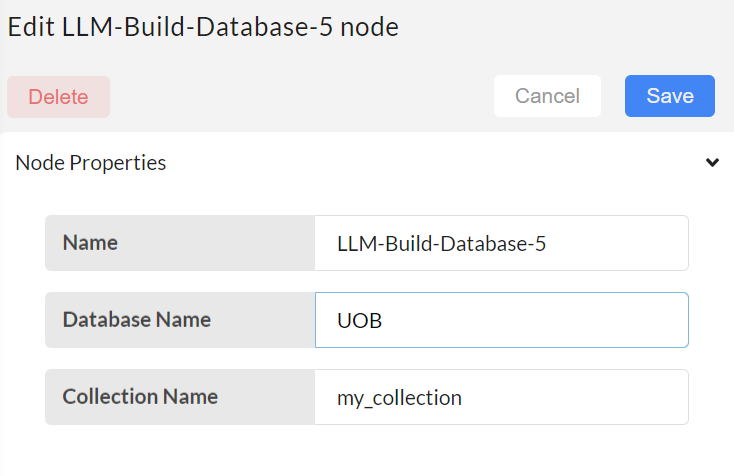
- Database name - specify the unique name for database.
After finishing the part 2 steps trigger the flow. The database will automatically create.
Inference Flow creation
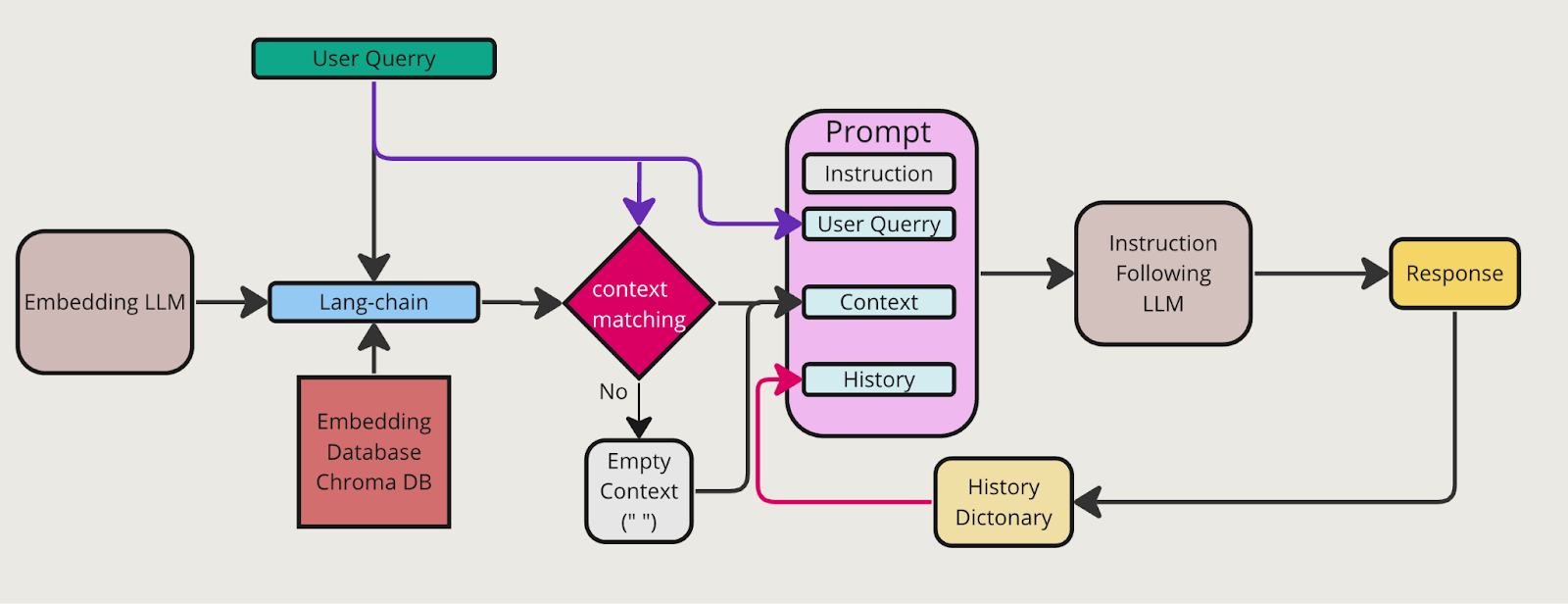
The above figure shows the overall functional flow of the chatbot inference.It should create the database before the inference flow. Thus , before the inference it must follow the data downloading steps and database creation steps.
Step 1
Following flow needs to be created to do the inference.

Step 2
Next step is to provide a Project name and Project type in the LLM-Initiate-Project-1 node.
Step 3
Configure the LLM-Embedding model loader. It will load the specific model for embedding.
Step 4
Next step is to configure the LLM-Inference-Model-Loader
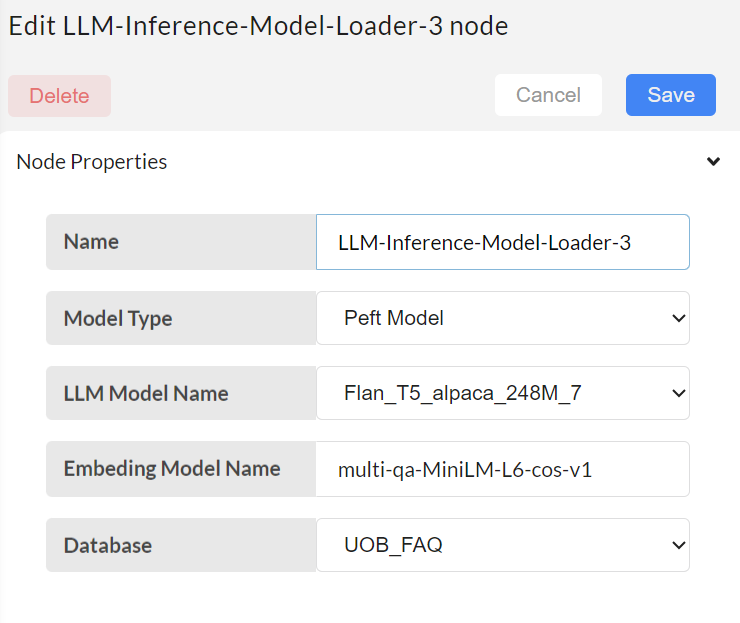
- Model type - select LLM model type for loading the model.
- LLM Model name - select a available model according to the type
- Embedding model Name - it can’t change in this node the value come from previous node
- Database - select builded database according to the embedding model.
Step 5
Next step is to configure the LLM-Semantic-Search node.

- Similarity threshold - set a similarity for semantic search in between zero to one.
Below threshold findings replaced with default value.
- Similarity Matrix - select similarity matrix for semantic search.
Step 6
Next step is to configure the LLM-Prompt-Generator node.
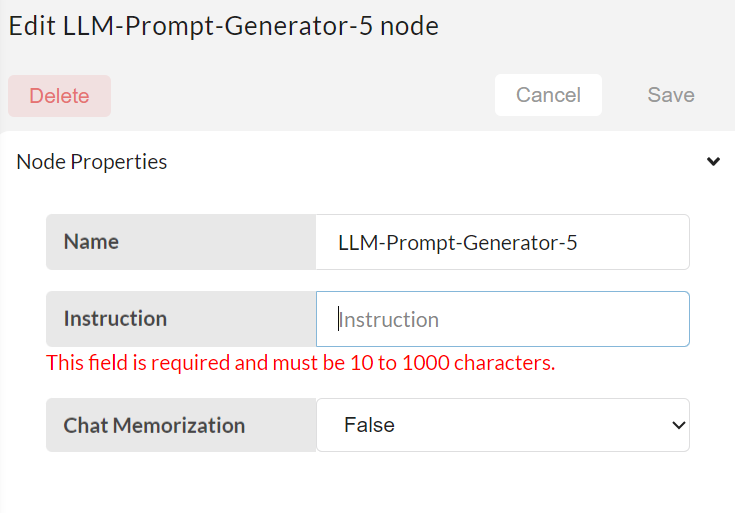
- Instruction - provide an instruction that chat-bots have to follow. It has a word limit; it is between 3 words to 100 words (for base model and peft models it is not mandatory).
- Chat Memorization - select true or false whether a chatbot has to follow the chat conversation or not.
Step 7
Next step is to configure the LLM-Response-Generator.
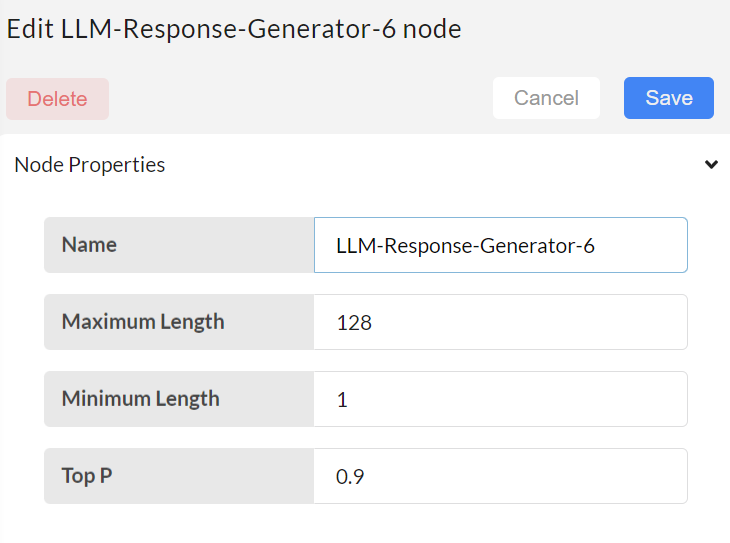
- Maximum length - limit of generated output text.
- Minimum length - minimum length of generating output.
- Top P - P index control the chat bot behavior with prompt lower value response to be more generalized, higher value responses to be prompt followed response. The value should be between zero to one.